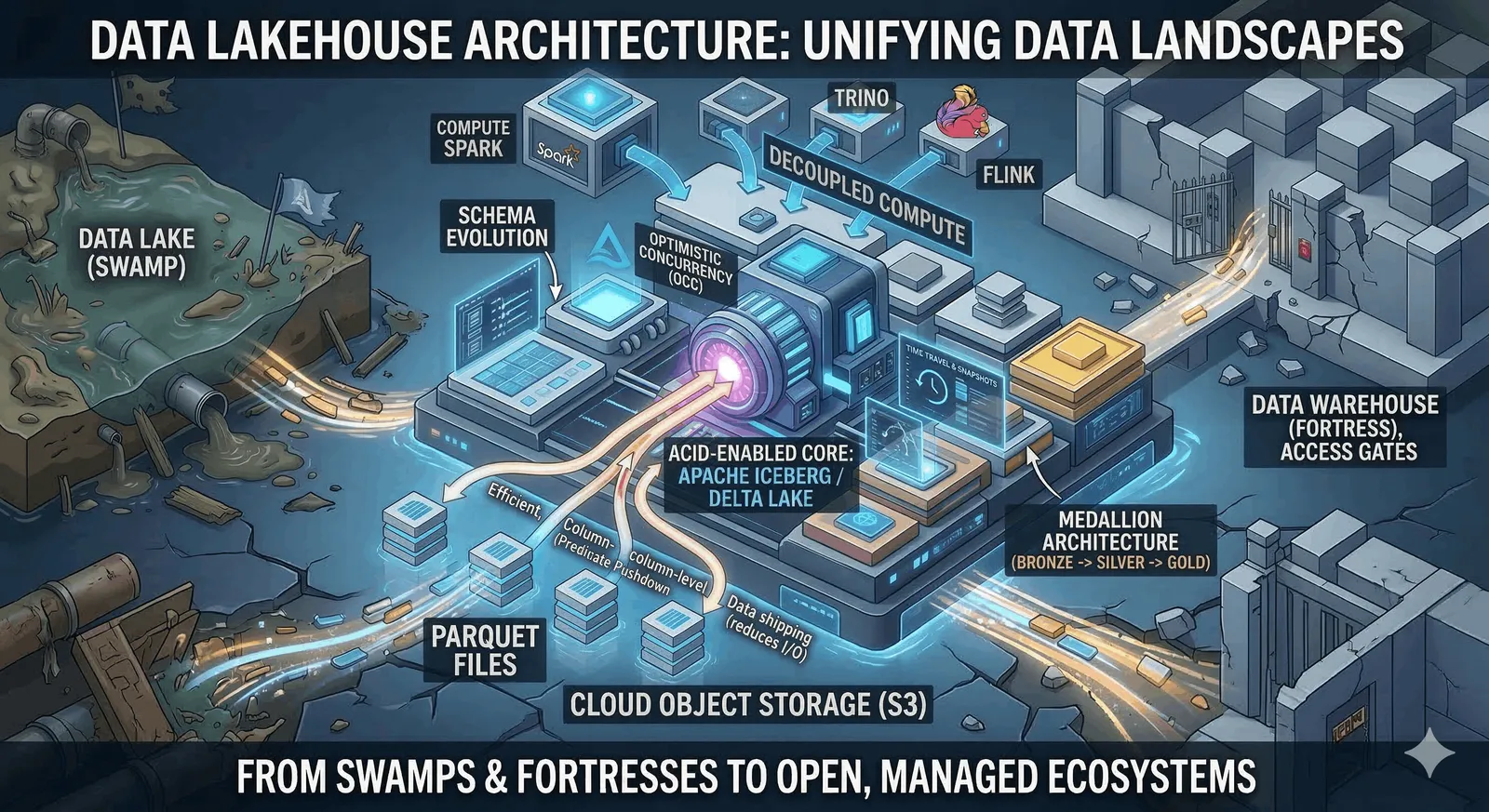
התקנו את Headroom ל-Claude Code ול-Codex ליום עבודה שלם. הנה מה שבאמת קרה
Headroom (headroom-ai) הוא שכבת context compression ל-AI agents שיושבת בין ה-agent ל-LLM ודוחסת את מה שהוא קורא לפני שזה נכנס למודל. בדקנו אותו תחת עומס אמיתי של Claude Code ו-Codex על macOS במשך כ-27 שעות. המסקנה: זה לא כפתור קסם, ולא כל מספר ב-dashboard אומר את מה שנדמה — אבל כשהשיחות מתארכות והקבצים משתנים, Headroom מתחיל להחזיר ערך אמיתי.

מאמרים נוספים