Apache Spark למפתחי Backend


9 דקות קריאה

אמ;לק
Apache Spark הוא לא “ספריית דאטה גדולה”. הוא execution engine מבוזר: אתם מגדירים pipeline לוגי על דאטה, ו-Spark מפרק אותו לעבודה מקבילית על cluster. כדי להבין אותו באמת, צריך להתחיל מ-RDD — אוסף immutable, partitioned ומבוזר של נתונים — ורק אחר כך לעבור ל-DataFrame ו-Spark SQL, שהן שכבות גבוהות יותר עם יותר מידע למנוע ויותר מקום ל-optimization. ברגע שמבינים את זה, גם groupBy, גם join, וגם count() נראים פחות כמו “syntax” ויותר כמו החלטות מערכת עם מחיר פיזי: CPU, זיכרון, דיסק, וחשוב מכולם — shuffle.
רקע: למה Spark מבלבל כל כך בהתחלה?
אם אתם מגיעים מרקע של Backend כמוני, האינטואיציה הראשונית סביב Spark בדרך כלל נופלת לאחת משתי מלכודות.
הראשונה: לחשוב שזה פשוט "pandas על הרבה מכונות״.
השניה: לחשוב שזה "SQL engine חזק״.
שתיהן נכונות חלקית, אבל שתיהן מפספסות את הנקודה המרכזית. Spark, לפי האתר הרשמי שלו, הוא:
multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters
כלומר, קודם כל זה מנוע הרצה; ה-API הוא רק הדרך לבטא עבודה.
זאת גם הסיבה ש-Spark מרגיש מוכר דווקא למהנדסי מערכות. יש. Driver, יש Executors, יש Resource Allocation, יש Parallelism, יש Locality, יש Failure Recovery, ויש מחיר אמיתי להזזה של state בין nodes. אם ב-Backend אתם רגילים לחשוב על latency, fan-out, hot-keys ו-network overhead - ב-Spark אתם פשוט מפעילים את אותה אינטואיציה על data flow במקום על request flow.
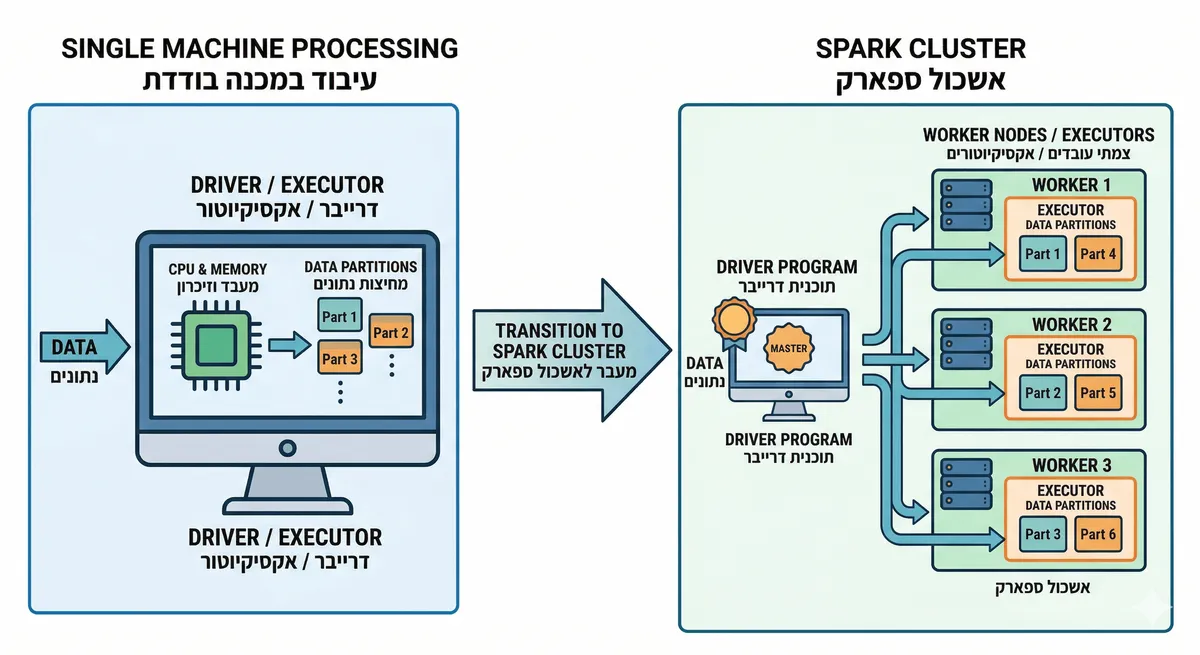
איך Spark עובד: להתחיל מהבסיס ולא מהקסם
RDD: אבן הבניין המקורית
האבסטרקציה הבסיסית של Spark היא RDD - Resilient Distributed Dataset. בתיעוד הרשמי הוא מוגדר כ:
collection of elements partitioned across the nodes of the cluster that can be operated on in parallel
ב-API עצמו הוא מתואר כ:
immutable, partitioned collection of elements
השם שלו מספר כמעט הכול:
Dataset - אוסף של רשומות
Distributed - האוסף מחולק ל-partitions על פני nodes שונים.
Resilient - אם חלק מהנתונים אובד, Spark יודע לשחזר אותו.
ה-"Resilient" הוא לא סתם מיתוג יפה. הוא אומר ש-Spark לא חייב לשמור כל intermediate result באפון מלא כדי להיות fault tolerant. במקום זה, הוא שומר את שרשרת החישוב - איך dataset נוצר - וכך יכול לחשב מחדש partitions שאבדו. זאת אחת הסיבות שה-mental model של Spark הרבה יותר קרוב ל-runtime מבוזר מאשר למסד נתונים קלאסי.
Partitioning: הסוד האמיתי של parallelism
RDD לא ״רץ במקביל״ בצורה קסומה. הוא מחולק ל-partitions, וכל partition יכול להיות מעובד בנפרד. זאת היחידה שמאשפרת ל-Spark לפזר עבודה בין executors. ה-parallelism שאתם מקבלים תלוי, בפועל, בכמה partitions יש, איך הם מפוזרים, וכמה העבודה עליהם מאוזנת.
כאן גם מתחיל ההבדל בין מערכת שנשמעת מבוזרת לבין מערכת שבאמת מתנהגת טוב בפרודקשיין. אם partition אחד ענק וכל השאר קטנים, קיבלתם cluster שלם שמחכה לעובד אחד. נשמע מוכר? זה בדיוק hot shard, רק על דאטה.
Transformations ו-Actions: lazy עד שכואב
המודל של RDD בנוי על שני סוגי operations:
Transformations: כמו
flatMap,filter,mapActions: כמו
save,collect,count
והנקודה החשובה: transformations ב-Spark הן lazy. כשאתם קוראים ל- filter אז Spark לא מתחיל לרוץ. הוא רק בונה תיאור של העבודה. רק כשמגיעה actions, הוא מפעיל execution בפועל. אם אתם מכירים reactive programming כמו reactor אז רק כשרשמים ל publisher מתחילה העבודה.
זה נשמע פרט טכני קטן, אבל זאת בעצם כל הפילוסופיה של Spark. אתם לא כותבים ״שלבים שמיד רצים״ אלא אתם כותבים תוכנית. ורק כשיש צורך המנוע מחליט איך לפרק אותו לעבודה מקבילית.
Driver, Executors, ו-Cluster Manager
כל אפליקציית Spark רצה כסט עצמאי של processes על קלאסטר. ה-Driver הוא התהליך שמריץ את הקוד הראשי שלכם ומחזיק את ה-SparkContext. דרך הדרייבר Spark מבקש משאבים מה-Cluster Manager (למשל Kubernetes) ומרים Executors על worker nodes. ה-Executors הם processes שמריצים בפועל את ה-tasks ושומרים דאטה בזיכרון או על הדיסק עבור אותה אפליקציה.
זה אומר משהו חשוב מאוד: ספארק הוא לא ״cluster shared cache" ולא "database". לכל אפליקציה יש את ה-executors שלה, וה-state הזמני שהיא שומרת בשביל עצמה בלבד. אם שתי אפליקציות רוצות לשתף תוצאה, הן בדרך כלל יעשו את זה דרך external storage, לא דרך זיכרון של ה-executors.
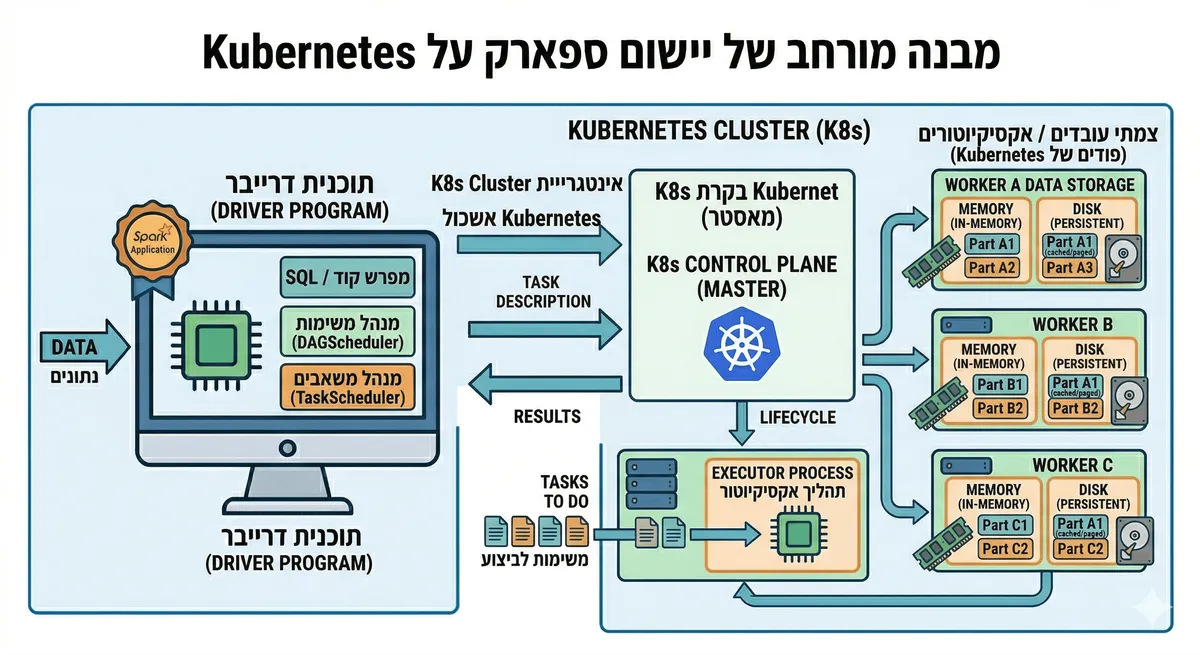
Jobs, Stages, Tasks: מהרמת יד ללכלוך אמיתי
כש-action מופעלת, ספארק מייצר Job. ה-job מתפרק ל-Stages, וכל stage מתפרק ל-Tasks. ה-tasks הן יחידות העבודה שנשלחות ל-executors. בפועל, מספר tasks קשור למספר ה-partitions שעליהן צריך לעבוד באותו שלב.
מבחוץ זה נראה חלק. בפנים, Spark בונה execution graph, מחליט איפה אפשר לבצע pipeline, ואיפה חייבים לעצור ולעשות redistribution של דאטה. כאן נכנס האויב הגדול של כל מי שאוהב latency קטן: Shuffle.
Shuffle: המס האמיתי של distributed data
אם יש מושג אחד שצריך לקחת מהפוסט הזה, זה לא RDD ולא DataFrame. זה Shuffle.
Shuffle קורה כשספארק צריך להעביר ולארגן מחדש נתונים בין מחיצות. זה קורה בדרך כלל בפעולות כמו groupBy, join, distinct, orderBy. התיעוד הרשמי של ספארק מגדיל shuffle כ-operation מורכב ויקר, ומציין מפורשות שהוא כולל data serialization, disk I/O, ו-network I/O.
וזה בדיוק המקום שבו הרבה הסברים למתחילים מפספסים. בעיה בgroupBy היא לא ״שסופרים הרבה שורות״. הבעיה היא שכדי שכל השורות של אותו key יגיעו לאותו מקום, צריך לארגן מחדש את הדאטה על פני הקלאסטר. כלומר, להזיז אותה ברשת, לכתוב intermediate data, לקרוא אותה מחדש ולשלם על כל זה.
במילים אחרות: פעולות מקומיות זולות יחסית. פעולות שמחייבות סידור מחדש של מחיצות הן המקום שבו ספארק מזכיר לכם שמערכות מבוזרות לא עובדות בלי תכנון מקדים.
אז איפה נכנסים DataFrame ו-Spark SQL?
אחרי שהבנו RDD, אפשר להבין למה העולם המודרני של ספארק עדיף לרוב על DataFrame/DataSet/SQL.
לפי התיעוד הרשמי, Spark SQL הוא המודול של ספארק לעבודה עם structured data, ובניגוד ל-RDD API, הוא נותן למנוע יותר מידע על מבנה הנתונים ועל החישוב עצמו. בגלל המידע הזה, ספארק יכול לבצע אופטימיזציות נוספות. באתר של Spark SQL מצוין גם שהוא כולל
columnar storage, cost-based optimizer, and code -generation
ב-Quick Start אפילו מנסחים את זה באופן די ישיר (תרגום ישיר שלי): אחרי ספארק 2.0 ה-main programming interface זז מ-RDD לכיוון Dataset, שדומה ל-RDD ברעיון אבל עם אופטימיזציות עשירות יותר מתחת למכסה המנוע. ה-RDD API עדיין קיים וחשוב להבנה, אבל הוא כבר לא ברירת המחדל לרוב ה-workloads structured
הניסוח הכי בריא מנטלית הוא זה:
RDD הוא המודל הבסיסי של ״אוסף מבוזר של איברים״. DataFrame הוא שכבה גבוהה יותר של ״טבלה מבוזרת עם סכמה״, שמאשרת למנוע להבין יותר ולעשות יותר.
אם אתם מפתחי בקאנד, אפשר לחשוב על זה כמו ההבדל בין לעבוד עם בייטים גולמיים לבין לעבוד עם typed protocol שה-runtime יודע לנתח ולמטב.
דוגמה פשוטה: קודם RDD ואז להבין מה באמת קורה
rdd = spark.sparkContext.textFile("s3a://logs/app/")
errors = rdd.filter(lambda line: "ERROR" in line)
count = errors.count()
מה קורה כאן בפועל?
textFileיוצר RDD שמחולק למחיצותfilterלא מריץ כלום, אלא יוצר transformation נוספת על אותו pipelinecount()היא פעולה, ולכן רק שם ספארק מפעיל job אמיתי
אם כל העבודה כאן נשארת מקומית לכל מחיצה, אין סיבה להזיז דאטה בין מכונות בקלאסטר. זה יחסית זול. אבל מהרגע שאתם עוברים למשהו כמו ספירה לפי מפתח, התמונה משתנה
דוגמה שניה: למה groupBy מרגיש תמים אבל לא תמים בכלל
from pyspark.sql import functions as F
users = spark.read.parquet("s3a://warehouse/users")
result = (
users
.filter(F.col("is_active") == True)
.groupBy("country")
.count()
)
לוגית מה שקורה פה זה פשוט: סנן, קבץ, ספור.
פיזית, זה סיפור אחר לגמרי. הfilter יכול לרוץ מקומית על מחיצות קיימות. אבל groupBy("country") בדרך כלל דורש שכל הרשומות של אותה מדינה יגיעו לאותה מחיצה לצורך אגרגציה. כלומר אנחנו מבצעים shuffle.
זאת בדיוק הנקודה שבה Spark מפסיק להיות ״API יפה״ והופך להיות מנוע שמתווכח עם הפיזיקה של הרשת.
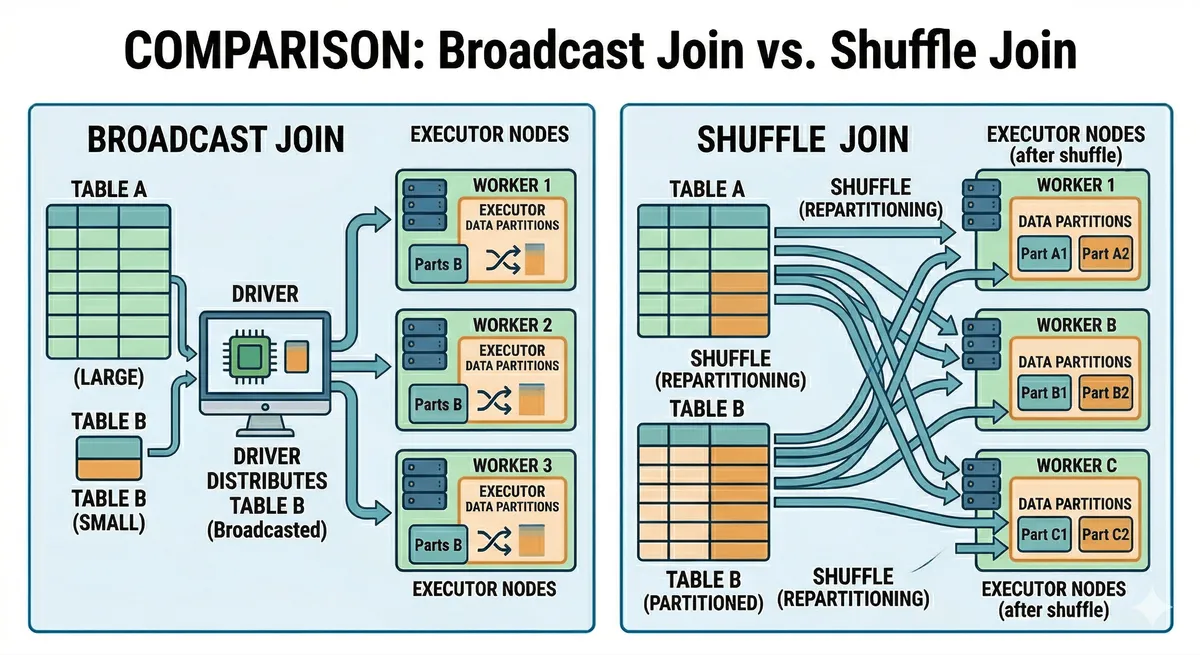
Join: לא תמיד אסון, אבל אסון כשאתם לא יודעים מה קורה
JOIN הוא המקום שבו Spark מפריד בין “כתבתי SQL” לבין “הבנתי execution”. לפי תיעוד ה-performance tuning, Spark SQL יודע לבחור אסטרטגיות join שונות, כולל broadcast, ויכול להשתמש גם ב-join hints כמו BROADCAST, MERGE, SHUFFLE_HASH ו-SHUFFLE_REPLICATE_NL. בנוסף, התיעוד של Spark 3.5 מציין ש-Adaptive Query Execution כולל בין השאר המרה של sort-merge join ל-broadcast join, coalescing של post-shuffle partitions, ו-skew join optimization.
זה אומר ש-JOIN לא תמיד חייב להיות “shuffle של שני צדדים ואז תפילה”. אם צד אחד קטן מספיק, Spark יכול לשדר אותו לכל ה-executors ולעשות local join מול הצד הגדול. זאת כבר חשיבה של מנוע execution, לא של שפת query.
Spark Infrastructure: המנוע הוא רק חלק מהסיפור
עוד בלבול נפוץ הוא לחשוב ש-Spark הוא “כל הפלטפורמה”. בפועל, Spark הוא המנוע, אבל הוא רץ בתוך סביבת הפעלה רחבה יותר: cluster manager, storage, submission, monitoring, logging ולעיתים גם orchestration מסביב. התיעוד הרשמי של cluster mode overview מתאר איך applications רצות כ-independent sets of processes על cluster, וה-cluster manager אחראי להקצות resources ל-Spark applications.
זאת הסיבה שכשמישהו אומר “יש לנו Spark infrastructure”, הוא בדרך כלל לא מתכוון רק ל-Spark binaries. הוא מתכוון לכל המערכת שמאפשרת להריץ workloads מבוזרים באופן אמין: אחסון נתונים, runtime, resource isolation, observability, retries, ולעיתים pipeline scheduler חיצוני.
מה Backend engineers בדרך כלל מפספסים
הטעות הראשונה היא לחשוב ש-Spark “יעשה קסם” גם אם לא אכפת לכם איך הדאטה מחולקת. הוא לא. partitioning ו-distribution הם חלק מה-design, לא פרט מימוש.
הטעות השנייה היא לחשוב ש-collect() הוא כלי תמים לבדיקה. אם אתם מביאים הכול ל-driver, ביטלתם את כל הרעיון של distributed execution.
הטעות השלישית היא לחשוב שה-API הגבוה מסתיר את המחיר. הוא מסתיר את התחביר, לא את הפיזיקה.
והטעות הרביעית, אולי הכי נפוצה, היא לדלג על RDD לגמרי. נכון, ברוב ה-production workloads תעבדו עם DataFrames ו-SQL, אבל אם אין לכם בראש מודל של partitions, lazy evaluation, actions ו-shuffle, אתם תכתבו קוד שנראה אלגנטי מאוד עד שהוא יפגוש dataset אמיתי.
סיכום
הדרך הכי טובה להבין Spark היא להתחיל מהבסיס: RDD הוא אוסף immutable ומבוזר שמחולק ל-partitions וניתן לעיבוד במקביל. מעליו הגיעו DataFrame ו-Spark SQL, שנותנים למנוע יותר מידע ולכן גם יותר כוח לבצע optimization. אבל לא משנה כמה ה-API יפה, המנוע עדיין חי בעולם של executors, tasks, network, memory ו-shuffle.
אם אתם מגיעים מ-Backend, זאת דווקא בשורה טובה. האינטואיציה כבר אצלכם. אתם כבר יודעים שמערכות נופלות על boundaries, על hot spots, על fan-out, ועל דברים שנראים “שורה אחת בקוד” אבל מתפוצצים בריצה. Spark פשוט לוקח את כל השיעורים האלה — ומלביש אותם על דאטה.
או במילים אחרות:groupBy הוא לא פקודה.groupBy הוא אירוע.