מ-Data Lake אל Data Lakehouse


4 דקות קריאה
אמ;לק
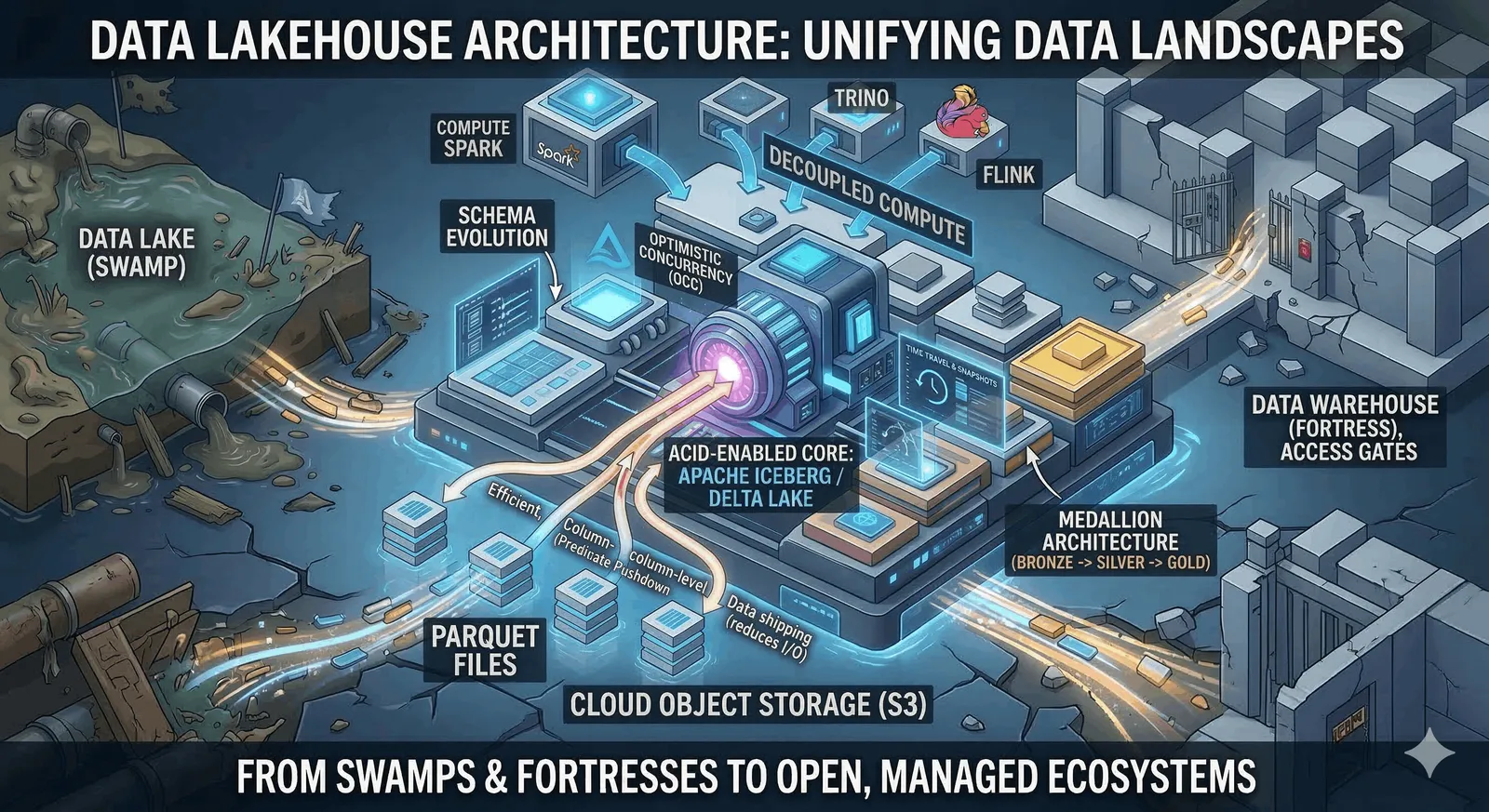
ה-Data Lakehouse הוא לא פשרה בין Data Warehouse ל-Data Lake, אלא אבולוציה שמייתרת את שניהם. באמצעות שכבת Table Format (כמו Apache Iceberg או Delta Lake), ה-Lakehouse מיישם Optimistic Concurrency Control, וניהול מטא-דאטה דטרמיניסטי על גבי Object Storage. התוצאה: יכולות ACID, פילטרציה ב-O(1), ו-Decoupling בין Compute ל-Storage - והכל בפורמטים פתוחים (open source).
רקע: האבולוציה והשבר של ארכיטקטורת הנתונים
כדי להבין למה ה-Lakehouse קיים, צריך להבין את הכאב הארכיטקטוני של העשור האחרון:
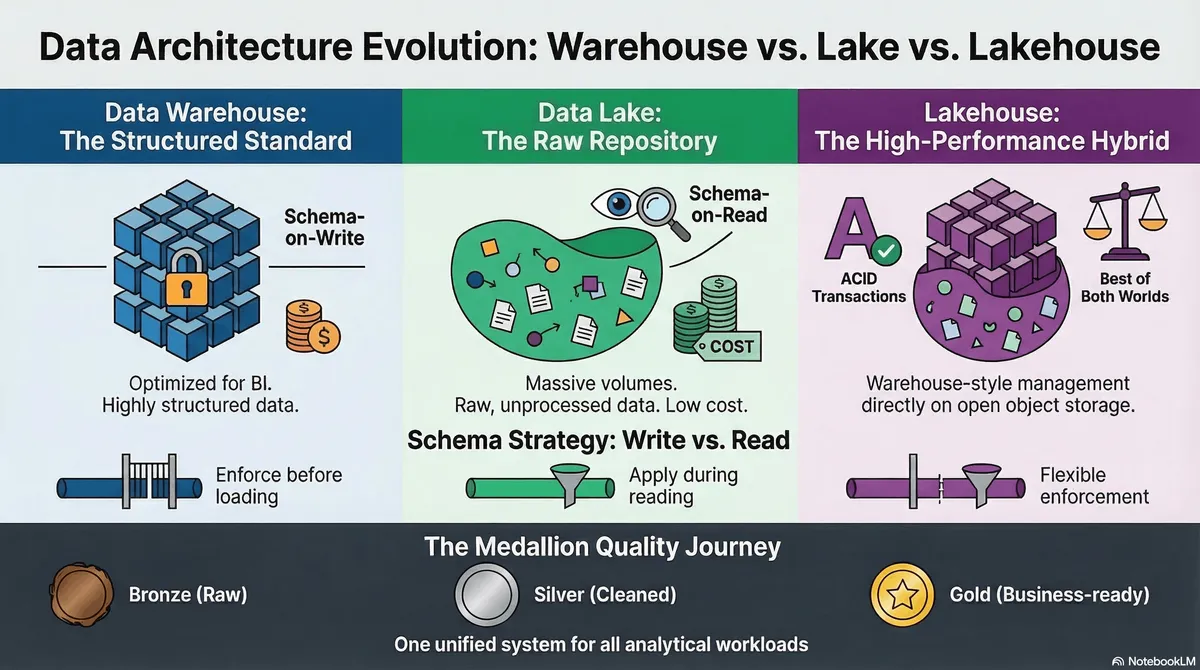
דור 1: ה-Data Warehouse (המבצר)
מערכות כמו Teradata, ואפילו הדורות הראשון של Redshift. בנויות על מודל של Coupled Storage & Compute או Shared-Nothing MPP.היתרון: ביצועים מטטורפים ב-OLAP, סכימה נוקשה (Schema-on-Write) וטרנזקציות ACID מלאות.
החיסרון: אחסון קנייני ויקר להחריד. אי אפשר לאחסן שם נתונים לא-מובנים (Unstructured), וכדי להגדיל את האחסון, לרוב נאלצת לקנות גם כוח מחשוב שלא היית צריך.
דור 2: ה-Data Lake (The Swamp)
כשה-Big Data התפוצץ, עברנו ל-HDFS ובהמשך ל-S3/GCS. שפכנו הכל לאחסון אובייקטים זול בגישת Schema-on-Write.היתרון: אינסוף אחסון בגרושים, גמישות מוחלטת בפורמטים (JSON, CSV, Parquet)
החסרון: קטסטרופה של Data Governance. אין ACID. אם תהליך Spark נכשל באמצע כתיבה, יש לך קבצים חלקיים ב-Bucket שמזהים את הקריאות של המשתמשים. כדי לעדכן שורה אחת (UPDATE/DELETE), היית צריך לקרוא ולשכתב partition שלם.
ה-Data Lakehouse (דור3) נולד כדי לחבר את ה-ACID והביצועים של ה-Warehouse, עם הגמישות והעלות האפסית של ה-Lake. איך? על ידי הוספת מוח (Metadata) לאחסון הטיפש.
איך זה עובד? שלוש השכבות של ה-Lakehouse
הקסם של ה-Lakehouse טמון בהפרדה חדה בין שלוש שכבות:
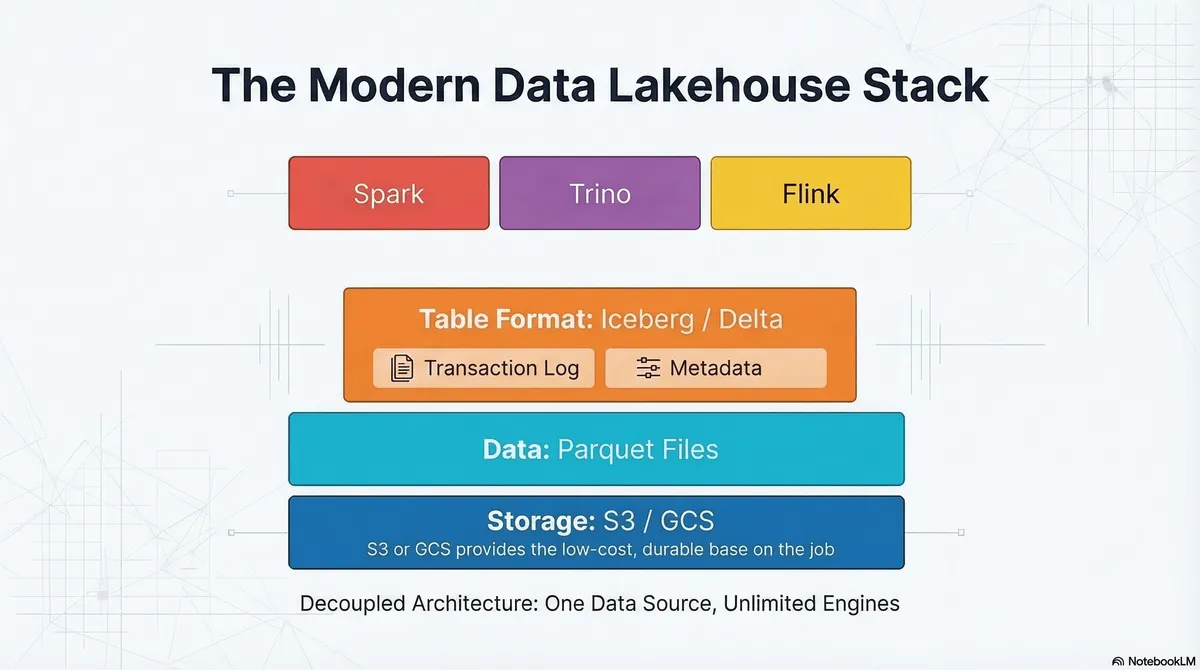
במקום שמנוע השאילתות (למשל Trino) ייגש ישירות ל-S3 ויבקש את הכל בצורה מאוד יקרה על אלפי תיקיות (זמן ריצה של O(n) בהתאם לכמות הקבצים) הוא פונה לשכבת ה-Table Format.
קוד ודוגמה מעשית: פתרון בעיית ה-UPDATE באגם נתונים
באגם נתונים מסורתי, כדי לבצע פעולת upsert (עדכון או הוספה) היה סיוט תפעולי שדרש תהליכי ETL כבדים. ב-Lakehouse, בזכות שכבת הטרנזקציות, מנוע המחשוב מטפל בזה ברמת הקובץ האמצעות פעולות כמו merge-on-read או copy-on-write
הנה דוגמת קוד מעשית עם PySpark מעל Apache Iceberg
from pyspark.sql import SparkSession
# Config session with Iceberg Catalog configuration
spark = SparkSession.builder \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.my_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.my_catalog.type", "hadoop") \
.config("spark.sql.catalog.my_catalog.warehouse", "s3a://my-lakehouse-bucket/") \
.getOrCreate()
# The MERGE INTO was available only on Data Warehouse
spark.sql("""
MERGE INTO my_catalog.db.users t
USING (SELECT * FROM staging_users) s
ON t.user_id = s.user_id
WHEN MATCHED THEN
UPDATE SET t.email = s.email, t.last_login = s.last_login
WHEN NOT MATCHED THEN
INSERT *
""")
מאחורי הקלעים, Iceberg לא משכתב את כל המידע. הוא יוצר Snapshot חדש שמציע על הקבצים הישנים שנותרו ללא שינוי, בתוספת קבצי Parquet חדשים (השינויים), וקובץ מטא-דאטה שמעדכן את עץ המצביעים.
ניתוח עומק: ההבדלים הטכנולוגים של ה Lakehouse
היררכיית מטא-דאטה ו-Query Planning ב-O(1)
באגם נתונים מבוסס Hive, התלות הייתה ב-Directory Structure. ב-Iceberg, המטא-דאטה בנוי כעץ:
Catalog -> Metadata file (current snapshot) -> Manifest List -> Manifest Files -> Data Files (Parquet)
כאשר אתם שולחים שאילתה, המנוע עובר על ה-Manifests ומבצע Min/Max Filtering ברמת הקובץ עוד לפני קריאת בייט אחד של נתונים מה-S3. חסכנו את סריקת התיקיות לחלוטין.
Optimistic Concurrency Control (OCC)
איך ה-Lakehouse מונע התנגשויות (Writer A מול Writer B)?
הוא משתמש ב-OCC: כל כותב מייצר קבצי נתונים חדשים מתוך הנחה שלא תהיה התנגשות. בשלב ה-Commit, כותב A מנסה לבצע Swap אטומי של ה-Metadata Pointer. אם כותב B הקדים אותו, כותב A קורא את ה-Metadata החדש, בודק אם השינויים שלו מתנגשים עם B ברמת הקובץ הפיזי. אם לא - הוא פשוט מנסה לעשות Commit שוב. זה מאפשר Throughput גבוה להחריד מבלי לנעול את הטבלה.
אבולוציית סכימה אמיתית
בפורמטים ישנים, זיהוי העמודה התבסס על שמה (Named-Based) או על מיקומה (Position-Based). ב-Lakehouse, לכל עמודה יש מזהה פנימי ייחודי (ID). שיניתם שם לעמודה? מחקתם אותה? התווספה חדשה? ה-ID נשאר קבוע ברמת המטא-דאטה. אין צורך לעשות Backfill היסטורי לדאט הישן.
Decoupling Compute & Storage ללא Vendor Lock-in
ארכיטקטורות מודרניות כמו Snowflake אמנם הפרידו בין מחשבון לאסון, אבל הנתונים שלכם עדיין יושבים בפורמט קנייני סגור. ב-Lakehouse, הדאטה שלכם יושב ב-Bucket שלכם, בפורמט Parquet פתוח. היום אתם יכולים לעבד אותו עם Spark (ל-ETL כבד), מחר לתשאל אותו עם Trino (לדוחות BI מהירים), ומחרתיים לחבר אותו ל-Amazon Athena - הכל על אותו עותק נתונים בדיוק.
סיכום
ה-Data Lakehouse הוא לא עוד ״כלי״, אלא התבגרות של אקוסיסטם ה-Big Data. על ידי העברת ניהול המצב (State), הטרנזקציות (ACID) והמטא-דאטה מתוך מנוע ה-Compute (המסורתי) אל שכבה פתוחה שיושבת ממש מעל האחסון - אנחנו מקבלים פלטפורמה אגנוסיטית, חסכונית בעלויות, שמכונה לעומסי עבודה המשלבים Data Science, Data Engineer, ו-Data Analysts תחת קורה אחת.